tar-vfs-index – Monter du .tar.gz dans le browser sans l'extraire

Distribuer des paquets binaires en WebAssembly, c’est galère. Vous téléchargez le .tar.gz, vous le gunzippez, vous l’extrayez en mémoire… et ça rame sévèrement !! Mais youpi, Jeroen Ooms (qui contribue à webR et bosse chez ROpenSci) vient de publier
tar-vfs-index
, un petit npm package qui casse cette malédiction des enfers en sautant carrément l’étape extraction.
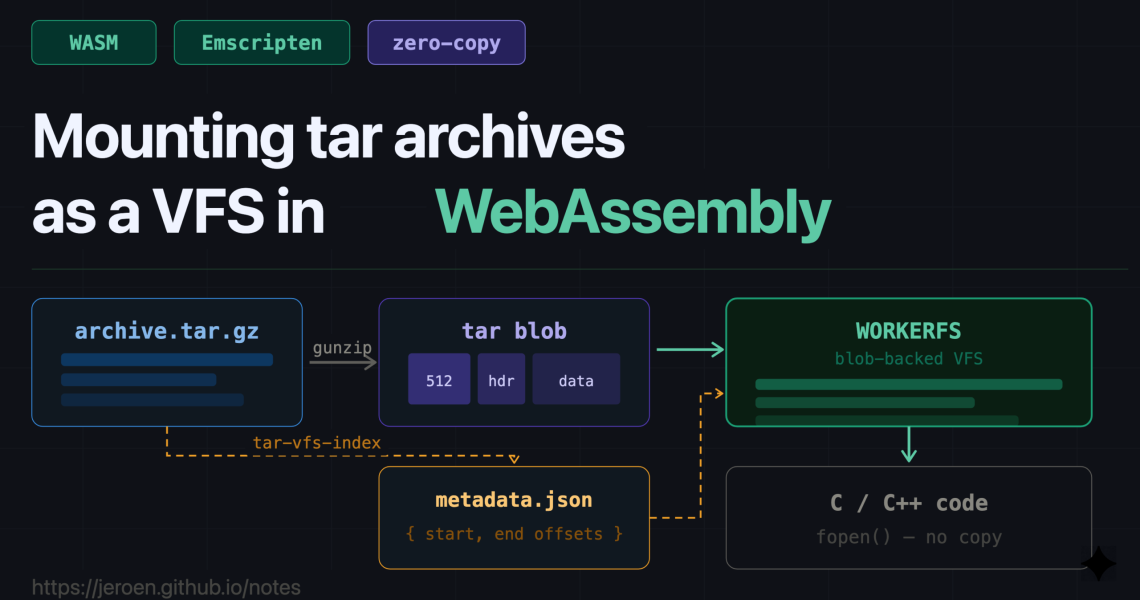
L’astuce est toute bête ! Au lieu d’extraire l’archive, on génère un fichier d’index qui liste la taille et l’offset de chaque fichier dans le tar. Du coup le navigateur n’a plus qu’à monter le blob du tar comme un système de fichiers virtuel, et chaque lecture devient alors un simple slice du blob à la bonne position. Pas d’extraction donc, mais juste du slicing à la demande !
Sous le capot, ça repose sur 3 propriétés alignées. 1/ le format tar est un layout plat : une suite de headers de 512 octets suivis des données du fichier, le tout contigu et adressable à l’octet près. 2/ Emscripten propose un backend filesystem appelé WORKERFS, prévu pour servir les lectures d’un Blob sans le copier dans le heap WASM. Et 3/ les navigateurs ont une API native,
DecompressionStream
, qui gunzippe efficacement pendant le téléchargement.
Concrètement, vous installez le truc avec npm install tar-vfs-index (y’a aucune dépendance externe) puis vous lancez npx tar-vfs-index archive.tar.gz. Et hop, le package vous sort un JSON dans ce genre :
{
"files": [
{ "filename": "mypackage/DESCRIPTION", "start": 512, "end": 548 },
{ "filename": "mypackage/R/code.R", "start": 1536, "end": 1563 }
],
"remote_package_size": 3072
}
Les valeurs start et end sont tout simplement les offsets dans les données tar décompressées, et remote_package_size indique la taille totale (pour que WORKERFS sache combien préallouer). Ensuite, côté navigateur, ça donne du JavaScript du genre :
const [metaRes, dataRes] = await Promise.all([
fetch('archive.tar.gz.json'),
fetch('archive.tar.gz'),
]);
const metadata = await metaRes.json();
const blob = await new Response(
dataRes.body.pipeThrough(new DecompressionStream('gzip'))
).blob();
FS.mkdir('/pkg');
FS.mount(WORKERFS, { packages: [{ metadata, blob }] }, '/pkg');
Le cas d’usage qui a motivé tout ça, c’est
webR
, le portage du langage R en WebAssembly. Les paquets R sont distribués en .tar.gz et avant cette astuce, charger un paquet voulait dire copier des trucs partout. Maintenant le temps et la mémoire de chargement reviennent à peu près au coût du téléchargement et du gunzip, ce qui est nettement plus léger qu’une extraction complète en RAM. Et ça marche pour n’importe quel bundle distribué en tar.gz : assets de jeu, datasets pour du machine learning, runtimes Python via Pyodide, bref tout ce qui ressemble à une archive lourde côté navigateur !
Y’a également un mode --append qui colle l’index directement à la fin du tarball (le format tar autorise ce genre de bidouille). Ça donne donc un .tar.gz autonome qu’un loader peut monter sans aller chercher un fichier de métadonnées séparé !
Bref, c’est plutôt joli comme façon de faire et ça vaut le coup d’œil si vous trimballez du tar.gz dans du WebAssembly.
Source : korben.info