Lemonade – L'IA locale sur NPU AMD, GPU et Mac

Vous n’avez pas de Mac Silicon, mais vous avez vu passer
mon article de ce matin sur vLLM-MLX
et son serveur d’IA local ? Hé bien bonne nouvelle, je suis tombé ce midi sur
Lemonade SDK
, un serveur d’IA local communautaire sponsorisé par AMD (et largement codé par leurs ingénieurs), qui joue dans la même cour, mais côté PC + Mac !
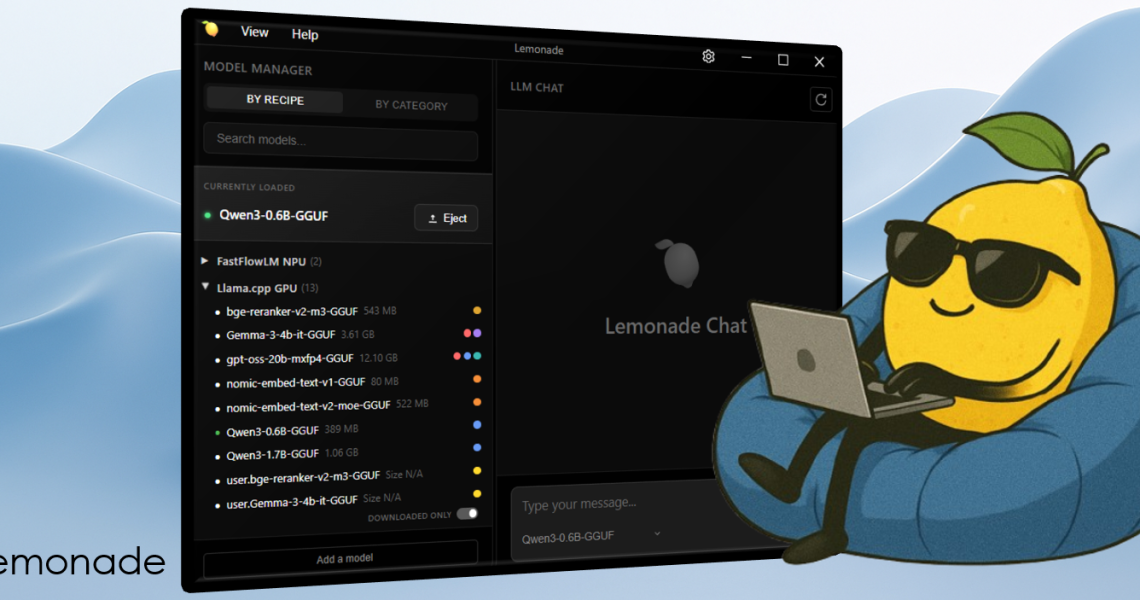
C’est la même logique qu’avec vLLM-MLX, vous installez le serveur (un paquet clé en main selon votre OS, pas de bidouille pip), et il expose un endpoint compatible API OpenAI sur http://localhost:13305/api/v1. Vos scripts tapent dessus au lieu d’envoyer vos prompts, et votre pognon, chez OpenAI.
Le démarrage tient en une ligne. Un lemonade run Gemma-4-E2B-it-GGUF lance un modèle, et un lemonade launch claude branche carrément Claude Code sur votre machine.
Sauf que là où vLLM-MLX s’appuie sur MLX pour les puces Apple, Lemonade vise les NPU Ryzen AI et les GPU Radeon. Et c’est tout l’intérêt du truc car depuis la 10.0 sortie en mars, le NPU XDNA2 des machines Ryzen AI récentes sert enfin à faire tourner des LLM sous Linux, et plus juste à décorer la fiche technique !
La 10.5 apporte également 2 nouveautés qui valent le coup. D’abord, le support macOS passe de bêta à officiel. Toutes les grosses fonctions sont validées sur Mac (le texte via llama.cpp et Metal, le reste via les autres moteurs embarqués) et ensuite, ça bascule sur ROCm 7.13 pour llama.cpp et la génération d’images.
J’ai pas de PC Ryzen AI sous la main pour tâter du fameux NPU, donc j’ai fait mes tests sur mon GPU Metal à moi. Notez qu’un lemonade list crache tout le catalogue, Qwen, Gemma, Llama, DeepSeek et compagnie.

Et ça dépote ! Un petit Qwen3-0.6B dans le chat intégré tourne à ~96 tokens par seconde avec mes 32 Go de RAM, c’est donc une réponse quasi instantanée. Après un modèle de 0,6 milliard de paramètres, c’est le poids plume du ring, donc comptez nettement moins sur un gros 8B, mais ça tourne nickel.

Du coup, sur Mac, vLLM-MLX joue la carte du natif Apple via MLX, alors que l’intérêt de Lemonade c’est surtout le cross-plateforme et le NPU Ryzen AI. Et comparé à
Ollama
, vous gagnez ce NPU mais aussi les fonctions audio (synthèse vocale, transcription) + un gestionnaire graphique de modèles pour piocher vos modèles. Et tout ça est sous licence Apache 2.0.
Bref, que vous soyez team Mac ou team Ryzen, c’est zéro ligne de facture API en fin de mois et surtout vos données qui restent chez vous !
Source :
Phoronix
Source : korben.info